
Figure 1: Sentiments!
Tagging the data
We continue working with the previous version of the data – with one word per row, with act, speaker, and genre marked – and now add: (a) stopword removal and (b) neg./pos. sentiment tagging.
We must concede that, although we have a version of the text here that is orthographically modernized, it’s still written in an old form of English with a number of words that are not included in a modern-day sentiment lexicon such as Bing Liu’s.
We can output a version of the text that has had the stopwords removed, and then shows us the words that were not mapped to a term in the sentiment dictionary (in other words, they were found neither in the stopwords list nor in the sentiment lists).
[1] "richard" "conqueror" "paucas" "pallabris"
[5] "world" "slide" "sessa" "pay"
[9] "glasses" "burst" "denier" "jeronimy"
[13] "thy" "bed" "thee" "fetch"
[17] "thirdborough" "fourth" "fift" "borough"
[21] "answer" "law" "budge" "inch"
[25] "boy" "huntsman" It’s not too terrible. Well – thee, thy etc. should have been removed as stopwords, but it’s alright. We can apply the method and trust it will tell us something informative Here, then, is the top of the list of words that were sentiment-tagged.
| speaker | word | sentiment | linenumber | act | genre |
|---|---|---|---|---|---|
| SLY | faith | positive | 1 | 1 | prose |
| HOSTESS | rogue | negative | 2 | 1 | prose |
| SLY | saint | positive | 9 | 1 | prose |
| SLY | cold | negative | 10 | 1 | prose |
| SLY | warm | positive | 10 | 1 | prose |
| HOSTESS | remedy | positive | 11 | 1 | prose |
| SLY | kindly | positive | 15 | 1 | prose |
| LORD | tender | positive | 16 | 1 | verse |
| LORD | poor | negative | 17 | 1 | verse |
| LORD | hedge | negative | 20 | 1 | verse |
| LORD | fault | negative | 20 | 1 | verse |
| LORD | lose | negative | 21 | 1 | verse |
Sentiment by Genre and Act
By Act
First, an analysis that foregrounds textual structure more than character. The data is aggregated accordingly…
| act | sentiment | n | total_tagged | prop |
|---|---|---|---|---|
| 1 | negative | 194 | 416 | 0.466 |
| 1 | positive | 222 | 416 | 0.534 |
| 2 | negative | 108 | 214 | 0.505 |
| 2 | positive | 106 | 214 | 0.495 |
| 3 | negative | 90 | 159 | 0.566 |
| 3 | positive | 69 | 159 | 0.434 |
…and then plotted.
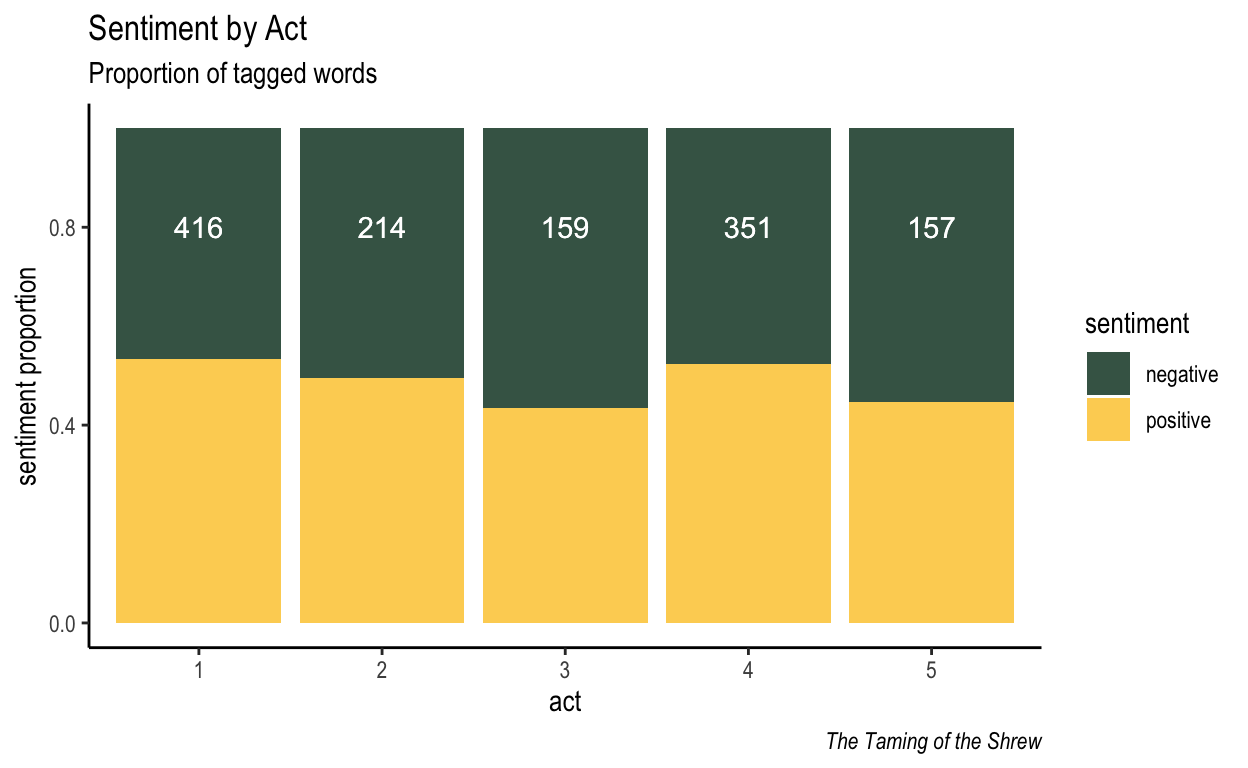
Figure 2: Sentiment per act.
By Act and Genre
First the data is converted…
| act | genre | sentiment | n | total_tagged | prop |
|---|---|---|---|---|---|
| 1 | prose | negative | 36 | 71 | 0.507 |
| 1 | prose | positive | 35 | 71 | 0.493 |
| 1 | verse | negative | 158 | 345 | 0.458 |
| 1 | verse | positive | 187 | 345 | 0.542 |
| 2 | prose | negative | 4 | 10 | 0.400 |
| 2 | prose | positive | 6 | 10 | 0.600 |
| 2 | verse | negative | 104 | 204 | 0.510 |
| 2 | verse | positive | 100 | 204 | 0.490 |
…and then plotted.
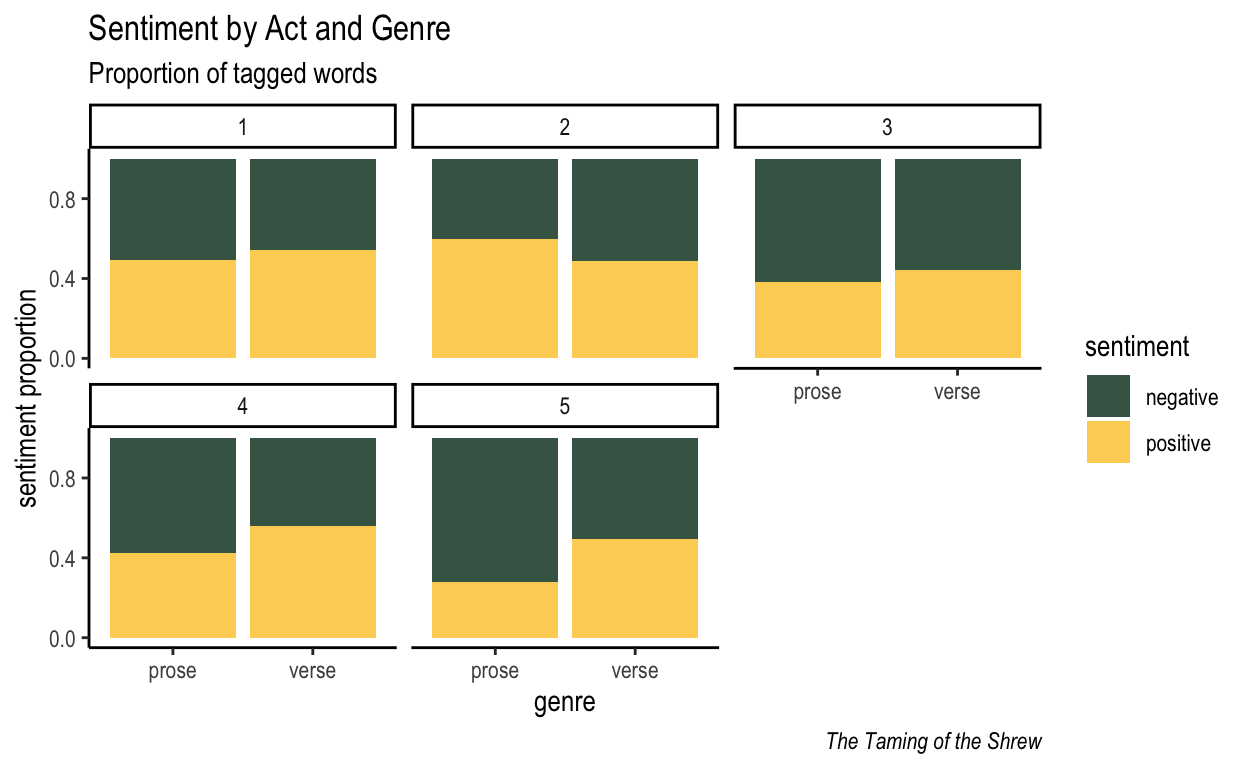
Figure 3: Sentiment per act and genre. Token counts are high enough for each act so the Ns aren’t reported (but cp. other plots below).
Sentiment by Character
We can produce a value for the proportion of neg. and pos. terms out of the total number of terms tagged for each character.
| speaker | sentiment | n | total_tagged | prop |
|---|---|---|---|---|
| BAPTISTA | negative | 41 | 79 | 0.519 |
| BAPTISTA | positive | 38 | 79 | 0.481 |
| BIANCA | negative | 19 | 36 | 0.528 |
| BIANCA | positive | 17 | 36 | 0.472 |
| BIONDELLO | negative | 21 | 43 | 0.488 |
| BIONDELLO | positive | 22 | 43 | 0.512 |
Let’s visualize these. Using proportions (or percentages) means that all the characters are displayed on the same scale, even though some of them have very, very few words. When a character has only a couple of words scored, there’s a bit of significance issue. Therefore I’ll include the number of words scored per character in the visualization: it will be proportional to the width of the bars for each character.
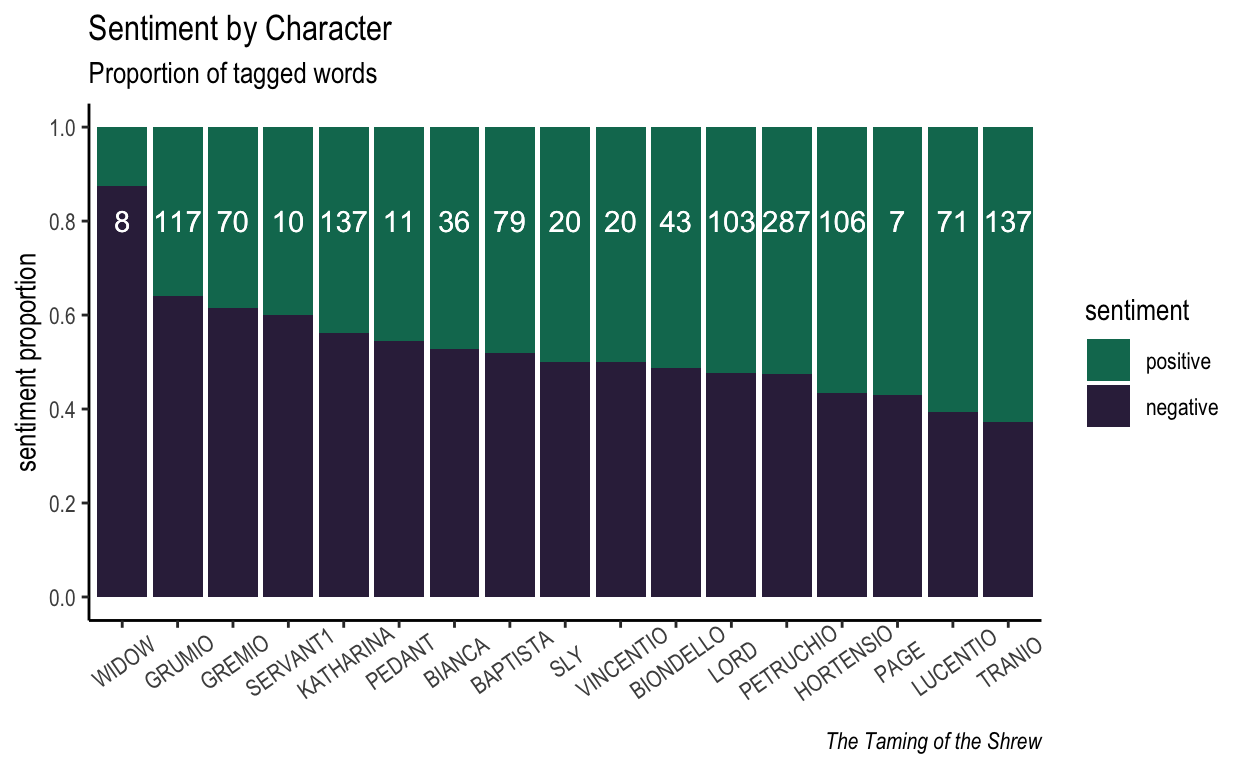
Figure 4: Proportion of sentiment scores per character. Label in white shows number of items scored per character as an indicator of reliability
Sentiment by Character and Genre
For this analysis, we break down the aggregate sentiment scores by character and genre. That is to say, we’ll end up with a dataset that contains (up to) four rows per character: it splits two ways for genre and then two ways for sentiment.
| speaker | genre | sentiment | n | total_tagged | prop |
|---|---|---|---|---|---|
| BAPTISTA | prose | negative | 5 | 7 | 0.714 |
| BAPTISTA | prose | positive | 2 | 7 | 0.286 |
| BAPTISTA | verse | negative | 36 | 72 | 0.500 |
| BAPTISTA | verse | positive | 36 | 72 | 0.500 |
| BIANCA | prose | negative | 1 | 2 | 0.500 |
| BIANCA | prose | positive | 1 | 2 | 0.500 |
| BIANCA | verse | negative | 18 | 34 | 0.529 |
| BIANCA | verse | positive | 16 | 34 | 0.471 |
| BIONDELLO | prose | negative | 18 | 35 | 0.514 |
| BIONDELLO | prose | positive | 17 | 35 | 0.486 |
| BIONDELLO | verse | negative | 3 | 8 | 0.375 |
| BIONDELLO | verse | positive | 5 | 8 | 0.625 |
Let us visualize these new numbers. A caveat: when there are too few items in a category (anything under about 4 has no statistical meaning), results must be taken with more than a grain of salt. Findings for the characters with more words can be trusted, however.
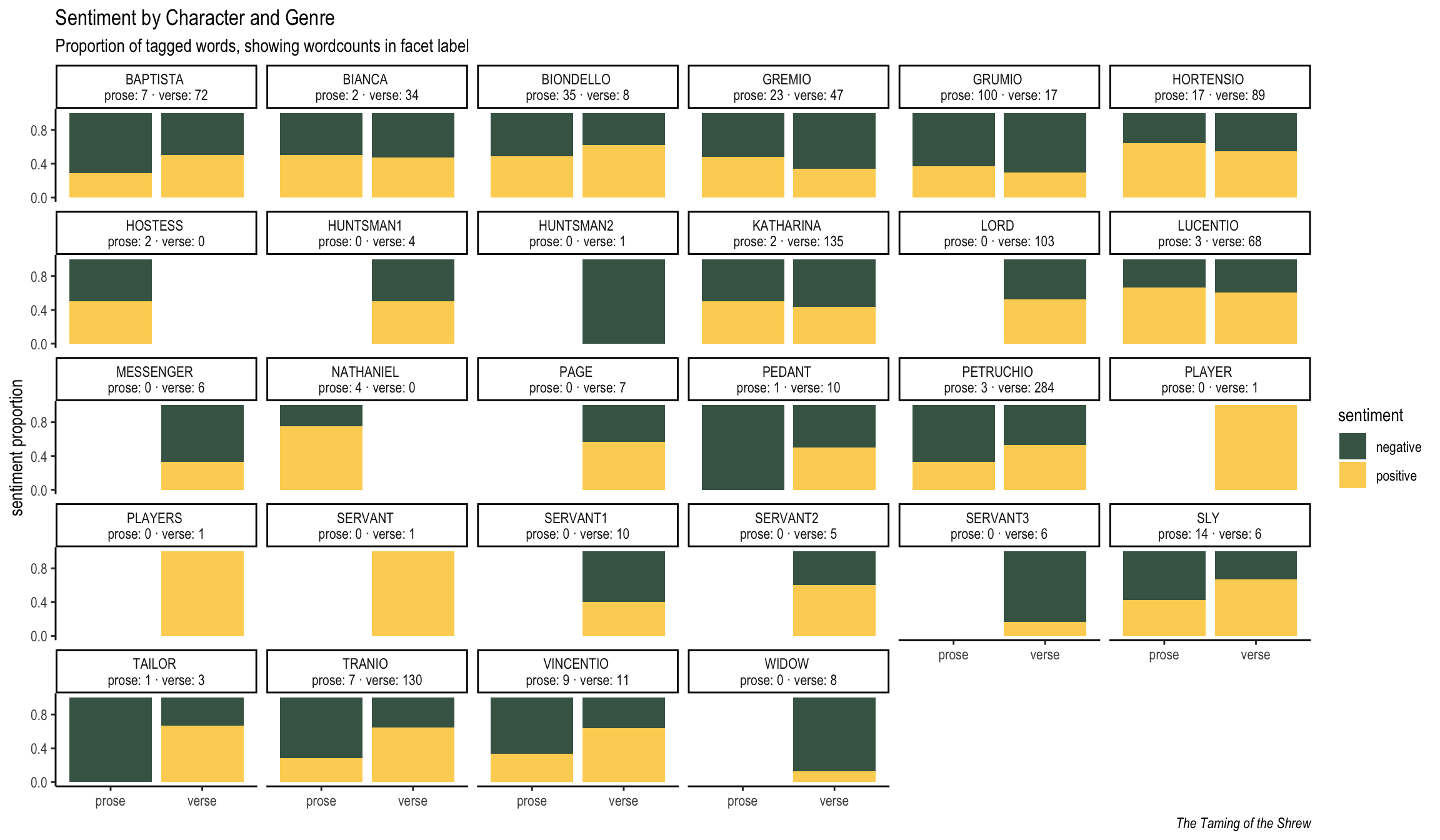
Figure 5: Crossing sentiment scores several ways.